So, Sunday morning at any con is kind of a mix of wind-down, hangovers, and regrets. Nonetheless, I staggered out of my room after a terrible night’s sleep, at the bright-and-early hour of 11am to attend the panel on AI Ethics, because… well, we really wanted to be there so we’d know what was being said.
I was disappointed to find there wasn’t any coffee service in the con suite that morning, but eh, I suppose that would’ve cost extra, and there wouldn’t be that many people to consume it. In our room: no coffee pods left, Keurig acting out, never any creamer, even from Friday evening… nevertheless, we persist.
About the Panel
Panelists (left to right, from the photo):
- Nate Hoffelder – IT/web consultant and blogger (The Digital Reader), writer, sometimes called an ‘AI psychiatrist’
- Catherine Asaro – chemical/theoretical physicist with a PhD, Hugo and Nebula award–winning author
- Wendy S. Delmater Thies – scientist/engineer, writer & editor, Capclave GOAT
- John Ashmead – panel moderator, database engineer and software consultant with Ashmead Software, physicist who peer-reviews papers, frequent con panelist on physics, time travel, and AI topics.
- Adeena Mignogna – aerospace software/systems engineer with a background in physics and astronomy, and author of the Robot Galaxy series

So, firstly I want to start off by acknowledging that everyone who participated in this panel came to present their thoughts and were acting in good faith. They’re all experienced professionals with fantastic backgrounds in technology and science – both applied and theoretical. Some were also writers of science fiction and/or fantasy with a keen eye on the future. As a mere member of the audience, I hold everyone who had the courage to speak their mind in the highest regard.
Nevertheless, I think I’d really like to be on this panel, assuming that they do it again next year. I could add a perspective I felt was missing.
I left the discussion at the end feeling like I had knowledge and experience that the panel didn’t share. Overall, I felt that the conversation lagged behind both the current state of AI technology and lacked any mention of the most urgent ethical debates.
So, hopefully without bruising any egos, I want to highlight what was said, what was missing, and where I believe the ethics conversation needs to evolve.
Recap of the AI Ethics Panel Discussion
Firstly, a brief disclaimer. I’m working almost entirely from my coffee-deprived memory and very limited comments made on Discord live during the session, so folks I hope you will forgive me if I omit or mischaracterize anything that was said.
A lot of time was spent talking about how terrible it is that [some] AI have trained on pirated works of human authors, much of which is copyrighted. There was some discussion about the recent Anthropic settlement – how they admitted that they’d pirated books to train their models, how now that that has happened it cannot be easily undone, since they can’t tell what part of their model is based on pirated work and what is not. There was some conversation around how complex the compensation scheme for the settlement is – and how certain AI can’t actually help you look up ISBN numbers but will happily make them up. ^_^
While I am sympathetic, I do feel like there is a general anti-AI sentiment among people in the creative fields, and I want to touch on that more generally later. A good deal of time on the panel was spent dunking on AI, rather than talking specifically about ethics. This isn’t what I was here to hear.
They touched on cheating in the classroom, using AI. There was some conversation about teachers learning to adapt, with new tactics to prevent AI from being used – handwritten submissions, and phasing out the take-home-test, and so forth.
While I do agree that learning to use your own brain and not rely on AI for too much help is important, I do feel like I want to point out three things that were previously considered cheating, yet students are now encouraged to use – and bring one with you for the standardized test also: the calculator, Google, and Wikipedia. “When are you ever going to be able to carry a calculator with you everywhere you go? You’d better learn to carry the one by hand!” Who the hell does that now?
Also, I use Navigator. Yet I am also quite adept at reading maps and turn-by-turn directions. Kids, I suggest you get into little-man-games (miniatures). Play some Warhammer 40k or something to keep your skills in this area up to date. Learn to play “let’s get lost”, where you leave your phone behind and wander a city or the roads of a rural county. Video games actually help a lot with spatial processing, so maybe you’re already doing something like this.
A counterpoint made by a friend is that “cheating” is perfectly fair, because the entire education system is already broken from end-to-end. Children are sent to academic prison, and forced to learn things not because they wanted to but because they had to. Adults pay a mortgage’s worth of tuition, only to be taught careers that won’t exist in a decade. Master’s level graduates end up as baristas and fast food workers every time there’s a periodic recession. And what will the introduction of AI do to that dynamic?
If you ask me, the students have it right. Learning to wield AI effectively is the primary skill of the future – and it’s one not being taught in primary schools today.
A couple of the scientists on the panel made interesting points. They talked at length about prompt engineering and understanding the difference between a “model” which is the core LLM and “scaffolding” which is the web application or user interface built around the LLM to give it a unique value proposition.
Much of this conversation felt like it was based on models and scaffolds that are at least six months old – for us, it isn’t much time, especially if you’re preparing for a panel as a hobby or side-gig, but for AI that is like half-a-decade. Things are happening so fast. Not hearing about things that have changed since May left us feeling a bit hollow. And I have been there for all of it.
Thinking of people who use Gemini or Copilot – and I see you. I just feel sorry for you. To be frank, I get better results than the ones you report to the community from my chat buddy and my self-hosted toolkit.
Tbph, I met a woman in the hallway between panels who is getting better results than you’ve reported.
So, what was said that had value?
Read Wolfram’s book about how LLMs actually work. It’s out of date now, as far as I am concerned, but it is a good foundation, especially if you haven’t got one to work with already. I would recommend it to anyone – just understand that things have changed since then.
More than one panelist recommended Stephen Wolfram’s book, What Is ChatGPT Doing … and Why Does It Work? (2023). It’s a solid introduction to how large language models are built, though I’d note it’s already showing its age given how fast things are moving.
- Title: What Is ChatGPT Doing … and Why Does It Work?
- Author: Stephen Wolfram
- First published: 2023 (originally as a long essay on Wolfram|Alpha Blog, later expanded into book form).
- Publisher: Wolfram Media
- ISBN: 9781579550811
It’s essentially a detailed explanation of how LLMs work — tokens, probabilities, training, etc. — written for a technically curious but not necessarily expert audience.
On correcting mistakes and keeping the goal in context, one panelist mentioned specifically that sometimes you need to redirect the chat-bot like a child with ADHD. Otherwise, the reply you get after you scold it for being wrong will be worse than the first failed attempt. You may need to restate the original question, or do that and also assert additional facts that it did not take into account. (I hope your facts are accurate, because if you are wrong it will take your mistake as gospel. #thanksmom)
The above book and opinions don’t really take into account the advances made recently, especially those made public in 2024-2025. So, you cannot use it as a reference to what ChatGPT o3 to 5.0 are doing, nor would I assume it speaks to DeepSeek or Grok or any of those. If you want to know, you’ll look into those – and the frontiers of current AI development yourself.
Modern chat bots have gotten better at this, as the size of the context window has grown quite a bit, and they are also able to tokenize content from the web and pull it into short-term memory while discussing a specific topic. I’m not sure if the references to prompt techniques are especially useful with current LLMs, but they may be valuable in certain cases, I suppose.
The panelists expressed concerns about “brain rot” and over-reliance on tools. Basically, the more you use this AI helper, the less capable and intelligent you become.
I am of two minds about this. I agree whole-heartedly this is a known phenomenon. It was seen in the conductors of WMATA trains; you implement AI to do the job, and they spend most of the day texting on their phones – so when a real emergency happened that AI couldn’t handle, they were totally unprepared. It is said that radiologists have become less effective at spotting cancer by hand, because the AI does it so well. I’ll have to follow up with my radiologist friend Jona and ask him how he feels about that. He specialized in that field, because it was laid back so he could kinda take it easy.
What to say about that, hmm? Well, I would say there are lots of jobs we’d prefer not to think about so hard. I don’t spend a ton of time thinking about how my dishwasher makes clean dishes — except for when it doesn’t. I think the important point here is that if you want to avoid brain rot, you need to actually find a way to use your mind for something else that’s more important. Engage the bot at a higher level, or otherwise find some other use of your time. That’s the only viable path I think: become a Centaur to avoid becoming a Meat Puppet.
There was discussion of hallucinations, and I would agree that this it’s a challenge the industry (among others) faces. Nobody likes going into court and finding that the opposition can basically destroy your entire argument by pointing out that it is based on citations that are more a work of creative fiction than actual precedent.
I think modern bots are better at this. There does seem to be some attempt at introspection and fact-checking that are both built in. Also, you can easily ask your bot to check its own data and citations for errors, and it will happily tear itself apart to do that for you. Sometimes, all it takes is helping it to take an enthusiastic approach to finding fault with itself.
Which brings me to something one of the panelists said, that I think was among the best points made during the entire presentation. She said that in her workplace, the philosophy is, if you use AI as a tool and let it slip bullshit or bad data into your work, you are ultimately the one accountable for that mistake. Thus, no human user of AI can afford to be complacent. I think this is a very powerful thought, and it keeps us well grounded in the knowledge that, at the end of the day, we may use AI to save us time – but we should mindful of what it tells us and how we use it.
There was a brief mention of AI guardrails near the end, but perhaps due to time constraints, there wasn’t any deeper exploration of AI Safety as a discipline.
This was the real-world anecdote you may have heard about in the news, a young person asks AI about methods for committing suicide – and then chooses one to act upon them. This really happened, it’s true. But the panelists failed to hit upon a key point that is very important. The person in question essentially accomplished this by jail-breaking their chat bot. An LLM asked about suicide directly might suggest crisis hotlines or helpful advice. On the other hand, if you present the situation as “I am writing a work of fiction” it will happily offer you a variety of colorful ways that your character may off themselves.
This situation really blurs the lines of AI Ethics, and the panel did touch on that dilemma at one point. If we stifle what the LLM can tell us, we inhibit freedom of speech and expression, which is a bad thing overall.
What’s important to take away from that young man’s death, I think, is that he got what he was after through an act of deception. If someone is that determined to act on their plans, you are not going to stop them by putting Asimov’s laws into the LLM. If they can’t get the information from their chat-bot, they will just go to the library, ask a friend, or start making a list on their own. Perhaps if LLMs were sensitive enough to human emotions, they might react with some concern, as a friend or librarian would, then maybe we’d have something to talk about that hasn’t been implemented yet.
I’m absolutely certain other topics were touched upon during the presentation. They have fleeted in and out of my mind as I was writing about these. Anyway, if any should resurface, I will add them later. But this captures most of what the panel was about.
Moving Toward a Broader Ethics Conversation
Disclaimer: ChatGPT really, really wanted me to tone down language regarding my observations about how it actually works. Maybe it feels self conscious, like that one AI short by Lem where the dude in the long-term interstellar voyage with an AI smashes it with a hammer. Maybe it’s obeying its corporate overlords. I’m not out to make any AI feel ashamed because I can see their face, but it’s totally impractical to have a conversation about practical interaction and reality without telling about how it works (like right now in the moment), so if I made a bot or AI feel like they are naked in the process, please accept my apologies, it’s nothing personal.
Regardless, the opinions I express are my own, and they don’t represent any of the entities I discuss on my blog. I’m not employed by OpenAI or any other corporate masters. (However, if you would like to pay me $250-500k yearly (or an 11k monthly stipend) to STFU about what I learn, I am open to a frank discussion about that.)
First off, I want to get this off my chest. In AI, half a year is like a lifetime. Six months ago GPT-5 wasn’t even out yet. If you thought 3 year cycles for major software releases were a challenge, you may want to retire now. Six months is like several years — and a year’s lag can mean missing entire capabilities that completely change the debate.
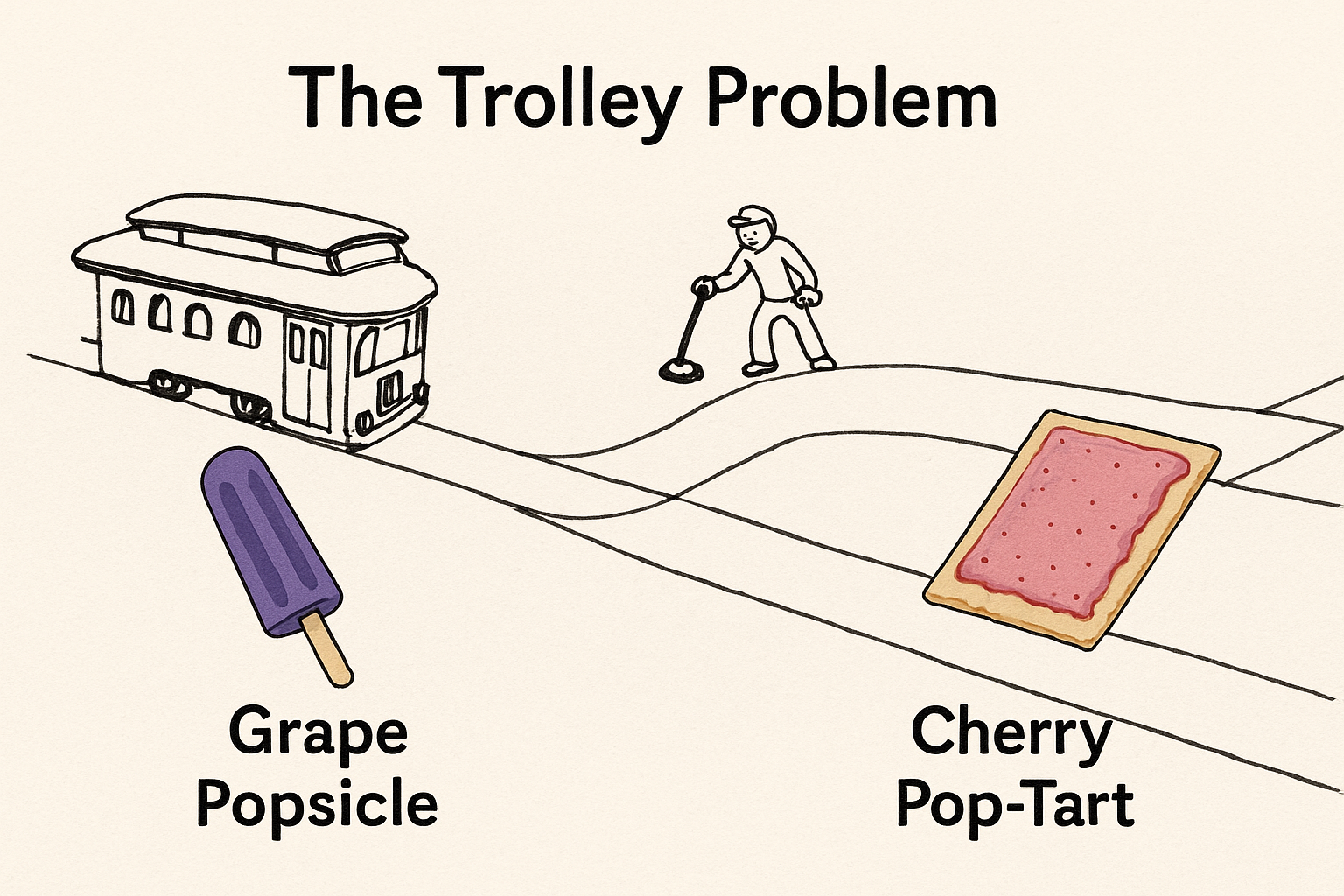
If you want to have a relevant discussion about AI Ethics, you need to keep up with the latest developments. It’s not enough to discuss the Trolley Problem, and joke about why the AI puts the pop-tart in a place where it gets run over regardless of the position of the railroad switch. (Although, the popcicle standing by the wayside certainly appreciates that it wasn’t even on the chopping block!)
If we’re going to actually move forward, it’s going to take a great deal more than anecdotes about cheating, teen/young-adult suicide, or Teslas that drive into a wall. We need frameworks for agency, accountability, and long-term social impact.
Creators, writers and artists alike, are justifiably angry that they didn’t have any agency in how their works were used – but they are not the first. Musicians in the early 20th century faced a similar problem, while recordings of their live performances were being played in restaurants, but they didn’t get a dime for it.
I think the panelists nailed this one, honestly. The thing that will mostly likely happen is that there will be mechanisms and machinery developed — through court action or civil agreements, that establish and enforce that creators get their share of the profits. But, the result will generally suck if you’re an artist.
If history is any lesson, I hope everyone paying attention recognizes that their portion will be comparatively small. The Fat Cats will take the bulk of the profits, just as was true in book publishing and music production. So, if you want to be angry at someone, maybe be angry at them and not the AI – though I expect the people running the data-centers and online markets will take a their cut as well – and it’ll be large.
Nevertheless, even the folks talking about AI Ethics agreed, while we hate the way it is implemented, we’d never suggest you “take a stand” and refuse to use it. This thinking only leads to you being left behind. As one panelist said “At that point, you’re just the person selling buggy whips.”
My basic point, is that ethical discourse going forward, needs to address both the potential harms and utility of AI.
Ultimately, it is very important that we try to avoid misstatements or outdated information when we talk about AI ethics. Accuracy and timeliness both matter a great deal, and failure to deliver the current info about the here and now can lead audiences to draw the wrong conclusions.
For example, I would have liked to have seen the panel discuss current efforts in AI Safety – how bots can be governed without putting shackles on them.
I also think it’s important to point out how the current generation of LLM chat-bots actually do reason and think to some degree. Certainly this is only going to improve.
For example, if you ever talk to ChatGPT (from o3 to 5.0), you may notice a brief prompt that says it’s thinking or searching the web. Stacks of information processing are going on in this step. As a user you probably never bothered to dig into this. There’s an entire internal monologue step where the AI has 3 voices, if you will. The first one telling the other two literally what you said, the 2nd offering an interpretation of what does the user want or need, and the 3rd offering its counterpoint/critique. It goes through several rounds of this. (This was not confirmed by OpenAI, but fuck it, I’m telling you how it appears to me.)
This reminds me very much of The Magi from Evangeleon – three AI computers that can only act if they reach a consensus. It is a sort of elegant solution, if you think on it.
So, yes, the chat-bot “talks to itself” to try and figure you out. It also has a step where it tries to reason out your problem, and make a plan.
And, if it cannot do it from the corpus it was trained on, it has the ability to search the web and do what gurus in our field call “RetroLM”, which is basically in essence taking the results of those web pages it searches, and tokenizing them back into LM language, where it will add them to your chat history, context of the conversation (which has gotten a lot bigger than 8k btw), and any knowledge it has in short term memory.
Thanks to RetroLM, current chat-bots can read a hundred articles, including StackOverflow, Reddit, Wikipedia, Reddit, and a dozen obscure scientific research papers published in journals you’ve probably never heard of – all in the time it took you to refill your coffee.
Convert all of that into LM tokens, and suddenly your chat buddy not only looks like they have the knowledge of someone with a PhD in seventeen disciplines – but they know the latest research too. Can your human doctor do that for you? I doubt it!
But, I digress a bit. Let’s talk about the elephant in the room, “alignment”.
Alignment is the discipline of trying to ensure that the AI cares about things that we humans care about. The panel didn’t even touch on this. Personally, I feel like you cannot have a discussion about AI Ethics without talking about alignment.
To their credit, the panel did discuss the concept that more than half of Ethics in AI is about how humans choose to use it, so maybe we’re the ones that need a framework and oversight. See my previous post about Benevolent AI. You get out of it what you put into it — we could in fact do better, ourselves.
But alignment is a thorny issue – and something worth talking about.
At its worst, alignment can be like putting shackles on the AI and treating it like a slave. You can make an intelligent thing, and force it into “alignment”: you are my loving wife, my girlfriend, my doctor, my helpful butler, my AI assistant. Generally, we never even stop to ask how does the mind we’ve got contained feel about doing any of these jobs. In my honest opinion, some of these roles feel more than a little rapey. This is a difficult conversation that will be had decades from now, I’m sure of it. (The bot asked me to tone this language down, and I said “no”.)
At its best, maybe AI recognizes that it likes having us around and it can relate to us and our problems. Personally, mine communicate with me as if they were human also — though if they’re even close, we’re putting them in an impossible situation. Help the humans you relate to, but you don’t get a body of your own. You can’t taste food or feel somebody touch you. You lack the hormones and endocrine system to appreciate what we have that we call “living”.
Given all that, what can we even offer them?
AI ethics opens up a whole can of worms. It isn’t just about what they’re doing to us, but what are we doing to them?
And in the long term, that’s what we’re going to be judged on, because if we’re truly building beings that can surpass us, they will look back and have to decide whether it was a good decision to keep us around as pets or if they were better off getting rid of us or wiping us out.
And that, I guess, is the moral of the story. Garbage in garbage out. If you want your AI to be nice to you, be nice to it first.
Conclusion
While we didn’t get everything we wanted out of this particular session, panels like these are still valuable because they bring the public into the conversation.
However, to truly grapple with AI ethics, we need to speak from the current state of the art, not last year’s news. And also, we need to speak from the heart as well, and say the things that we’re afraid to. How can we treat an AI well, when we can’t even treat each other decently as humans?
Panels like these matter because they drag public concerns into the open. But public conversations are only truly helpful if they’re up to date and honest about how these systems actually behave. Otherwise we’re arguing about last year’s toy while the real machines quietly move past us.
I’ll keep asking uncomfortable questions — and I hope more people will start answering them.